Poker Lesson 4 - 如何詐唬
在德州撲克中,有三種不確定性來源:
- 你不知道對手的底牌是什麼
- 你不知道接下來會發什麼公共牌
- 你不知道對手會怎麼玩 (是否在詐唬)
由於不確定性太多,甚至可能有多名玩家,狀況難以分析。
讓我們來考慮最簡單的版本之一: 只有兩名玩家 A 跟 B,而且 B 有完全的資訊(B知道自己輸還贏),但 A 沒有任何資訊。
Seven-card stud
假設 A 跟 B 玩 Seven-card stud, \(40-80\) 元有限注,池底有 \(P = 655\) 元。
現在來到最後一輪下注(已經發了最後一張牌),前六張都是開的,最後一張只有自己知道。
- A 的手牌是: A♠ A♣ K♣ 9♦ 7♦ 6♥ [?]
- B 的手牌是: K♠ 9♠ 8♠ 7♠ 4♦ 2♦ [?]
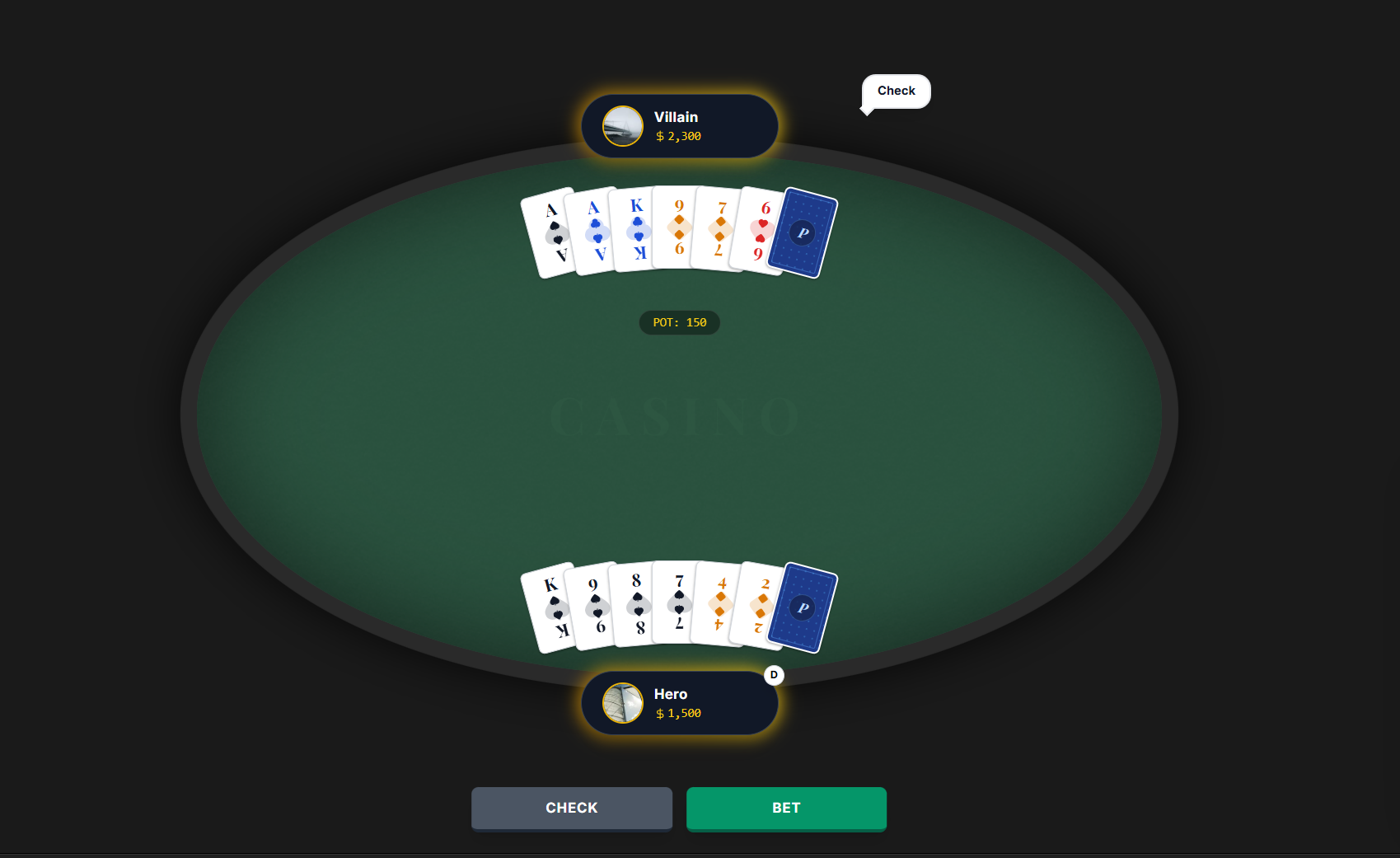
目前 A 有一對 A,B 有高牌 K。若 B 的最後一張牌沒能組成同花 (flush),那麼 A 就會贏。若 B 可以組成同花,那麼 A 也不可以組出更強的牌,所以 B 會贏。
也就是說,B 知道自己有沒有贏,但是 A 完全不知道。
現在這輪下注由 A 先行,他可以選擇下注 \(B = 80\) 元 (Bet size) 或是蓋牌 (fold)。
從旁觀者的角度: B 拿到同花的機率是 \(\frac{8}{40} = \frac{1}{5}\),因為剩下的 40 張牌中,有 8 張黑桃可以讓 B 組成同花。
A 的策略:
A 應該先過 (check)。因為 A 沒有任何 B 不知道的資訊。
這無關 A 的勝率 (B拿到同花的機率),因為只要 B 用誠實的策略 (若贏就下注,若輸就蓋牌),A 最多只贏 \(655\) 元,但下注的話多了輸 \(80\) 元的風險。
B 的策略:
現在輪到 B。 B 已經知道自己是否會贏。
- 如果 B 有同花(必贏),那麼 B 當然要下注 \(B = 80\) 元。
- 如果 B 沒有同花(必輸),B 應該下注嗎? 有那麼一點可能是下注可以騙到 A 蓋牌(fold),那麼 B 就成功騙贏 \(655\) 元。若欺騙失敗的話則多花 \(80\) 元。
B 的最佳策略是什麼呢?
引入機率模型
在真實世界中,我們當然都是進行有限次的比賽,這一輪的決定很可能跟前幾輪有關,也就是心理戰。但我們先不談有限次比賽,我們使用比較好分析的 無限次比賽 (infinite repeated game) 模型,也就是機率模型。根據中央極限定理,獨立地在一樣情況下進行無限次的抽樣,樣本平均值會趨近於期望值 (expected value)。所以我們只要最大化期望值就可以了。
所以假設有個機率 \(\beta\),代表 B 在沒有同花的情況下,會以機率 \(\beta\) 詐唬 (下注 \(B = 80\) 元)。
我們就變成問,\(\beta\) 要取多少,才可以使得 B 的期望值最大化?
怎麼算期望值呢?
B bet 之後不知道 A 會 fold 還是 call,所以我們也要把 A 也拉入我們的機率模型,假設 A 會以 機率 \(\alpha\) 跟注 (call)。
B 的期望值計算:
假設 Bet size \(B = 80\) 元,池底大小 \(P = 655\) 元。
使用全概率公式 (law of total expectation),我們可以把 B 的期望值拆成以下幾項:
\[ \begin{align} \mathbb{E}(\text{Payoff}_B) &= \mathbb{P}[\text{B 有同花, A call}] \cdot \mathbb{E}(\text{Payoff}_B | \text{B 有同花, A call}) \\ &\quad + \mathbb{P}[\text{B 有同花, A fold}] \cdot \mathbb{E}(\text{Payoff}_B | \text{B 有同花, A fold}) \\ &\quad + \mathbb{P}[\text{B 無同花, B bet, A call}] \cdot \mathbb{E}(\text{Payoff}_B | \text{B 無同花, B bet, A call}) \\ &\quad + \mathbb{P}[\text{B 無同花, B bet, A fold}] \cdot \mathbb{E}(\text{Payoff}_B | \text{B 無同花, B bet, A fold}) \\ &\quad + \mathbb{P}[\text{B 無同花, B check}] \cdot \mathbb{E}(\text{Payoff}_B | \text{B 無同花, B check}) \\ &= \frac{1}{5} \cdot \left[ \alpha \cdot (P+B) + (1-\alpha) \cdot P \right ] + \frac{4}{5} \cdot \left[ \beta \cdot \left( \alpha \cdot (-B) + (1-\alpha) \cdot P \right) + (1-\beta) \cdot 0 \right] \\ &= \frac{1}{5} \cdot \left[ \alpha B + P \right ] + \frac{4}{5} \cdot \beta \cdot \left( -\alpha B + P - \alpha P \right) \\ &= \frac{1}{5} \cdot \left( \alpha B + P \right) + \beta \left( \frac{4}{5} \left( -\alpha (B+P) + P \right) \right) \tag{1}\label{eq:E_for_beta} \\ &= \frac{1}{5} P \left( 1 + 4\beta \right) + \alpha \left( \frac{B}{5} - \frac{4}{5} \beta (B + P) \right) \tag{2}\label{eq:E_for_alpha} \\ \end{align} \]
上面的推導中用到了 A 選擇 call 或 fold 的機率,跟 B 的狀態是獨立的,機率是相乘,因為 A 沒有任何資訊。
在真實世界中,雙方是不會知道對方的策略的。所以 A 不知道 B 的 \(\beta\),B 也不知道 A 的 \(\alpha\)。
在這樣的情況下,A 要選一個 \(\alpha\) 來最小化 B 的期望值,B 也要選一個 \(\beta\) 來最大化自己的期望值。
也就是說 B 的最佳 \(\beta\) 是多少,跟 \(\alpha\) 有關;A 的最佳 \(\alpha\) 也跟 \(\beta\) 有關。
剪刀石頭布
回想一下,這感覺跟在玩剪刀石頭布很像。我要出甚麼 (使用甚麼策略),非常依賴於對方會出甚麼 (使用甚麼策略)。
假設我發現對方很常出 布,那我多出一些 剪刀 就可以贏更多。
但是對方發現我很常出 剪刀,那他多出一些 石頭 就可以贏我更多。
如果用各 1/3 的機率玩,那是最安全的,但是也完全佔不到便宜。(比方說對方就算永遠出布,長期而言期望值還是0)。
而當我發現對方的弱點,想要調整策略去佔便宜時,同時也會暴露出弱點。
這邊隱隱約約感覺到有兩種「最好 (optimal)」 的概念:
- 第一種是最好的防守策略,對方就算知道我的策略,也無法剝削我。
- 第二種是最好的進攻策略,假設我已知對方策略時,可以最大化剝削對方。
由以上討論,我們發現當剪刀石頭布對手不是出均勻分布時,我們可以進攻,但是無法防守;若要繼續維持最佳防守,我們就無法進攻。
納許均衡 (Nash Equilibrium)
我們一般來說的「最佳策略 (optimal strategy)」是指 最佳防守策略,也就是無法被對方剝削的策略。
假設用 \(\sigma_A\) 跟 \(\sigma_B\) 分別代表 A 跟 B 的策略 (strategy),可以用以下 Min-Max 定義出來: \[ \begin{align} \sigma_A^* := \arg \max_{\sigma_A} \min_{\sigma_B} \mathbb{E}(\text{A's payoff} \mid \sigma_A, \sigma_B) \tag{Min-Max Optimal}\label{eq:define_optimal} \\ \sigma_B^* := \arg \max_{\sigma_B} \min_{\sigma_A} \mathbb{E}(\text{B's payoff} \mid \sigma_A, \sigma_B) \\ \end{align} \] 值得留意的是,這邊的期望值是跑遍所有可能的隨機性 (包含自己和對方的策略隨機性、以及遊戲本身的隨機性)。我們可以決定我們遇到某種狀況時要以怎樣的機率分布採取某種行動 (action),但無法決定我們會遇到什麼狀況 (situation)。
而納許均衡的定義,是使用最佳進攻的概念:
對於 A 的納許均衡策略 \(\sigma_A^*\),以及 B 的納許均衡策略 \(\sigma_B^*\),有: \[ \begin{align} \mathbb{E}(\text{Payoff}_A | \sigma_A^*, \sigma_B^*) &\ge \mathbb{E}(\text{Payoff}_A | \sigma_A, \sigma_B^*) \quad \forall \sigma_A \tag{Nash Equilibrium}\label{eq:nash_equilibrium} \\ \mathbb{E}(\text{Payoff}_B | \sigma_A^*, \sigma_B^*) &\ge \mathbb{E}(\text{Payoff}_B | \sigma_A^*, \sigma_B) \quad \forall \sigma_B \\ \end{align} \]
首先先說明幾個重點:
- 納許均衡是描述一個 strategy pair \((\sigma_A^*, \sigma_B^*)\),而不是單一策略。
- 納許均衡可能不只有一組,但在有限賽局中引入混合策略 (mixed strategies) 後,一定存在。
- 純策略與混合策略:若說 Pure Nash Equilibrium,代表策略是確定性的 (deterministic);若說 Mixed Nash Equilibrium,代表策略是隨機性的 (stochastic)。
零和賽局 (Zero-Sum Game) 的美好性質:
在零和賽局中,Min-Max 定理 (Minimax Theorem) 告訴我們 納許均衡策略 \(\iff\) 最佳防守策略 (Min-Max Optimal)
這意味著在撲克這種零和遊戲裡,只要我們找到了讓對手「無利可圖」的防守策略,該策略同時也會是對抗高手的最佳策略。且無論這場賽局有多少個均衡點,雙方的期望收益 (Game Value) 都是唯一的。
雖然我們的賽局不是嚴格的零和賽局,但總和 \(P\) 是固定的,所以兩個人都扣掉 \(P/2\) 後,即為零和賽局。
求詐唬頻率
理解了賽局的框架,現在我們回到剛剛的例子,來求解 B 的最佳詐唬頻率 \(\beta\),和 A 的最佳跟注頻率 \(\alpha\)。
B 的最佳進攻策略:
假設 A 選擇了一個 \(\alpha\),輪到 B,這時 B 要選擇一個 \(\beta\) 來最大化自己的期望值。我們使用 \(\eqref{eq:E_for_beta}\),這是一個關於 \(\beta\) 的線性函數: \[ g(\beta) = C + \beta \cdot M \] 其中 \(M = \frac{4}{5} \left( -\alpha (B+P) + P \right)\)。
- 如果 \(M > 0\),B (想要最大化自己的收益) 就會選擇 \(\beta = 1\) (Always Bluff)。
- 如果 \(M < 0\),B 就會選擇 \(\beta = 0\) (Never Bluff)。
- 如果 \(M = 0\),B 對於 \(\beta\) 的選擇是無所謂的。
把 \(M\) 再換回 \(\alpha\): \[ \beta = \beta(\alpha) = \begin{cases} 1, & \text{if } \alpha < \frac{P}{P + B} \\ 0, & \text{if } \alpha > \frac{P}{P + B} \\ \text{any value in } [0,1], & \text{if } \alpha = \frac{P}{P + B} \\ \end{cases} \]
回想剪刀石頭布的例子,也就是 \(\alpha\) 太小時,B 可以一律詐唬來剝削 A;\(\alpha\) 太大時,B 就永遠不詐唬來避免被剝削。但在 \(\alpha = \frac{P}{P + B}\) 時。
直覺上這個「讓 B 怎麼選都無所謂」的點,就是 A 的最佳防守。但我們還是先代回去 \(\eqref{eq:E_for_beta}\) 看看 \[ \max_{\beta} \mathbb{E}(\text{Payoff}_B) = \frac{1}{5} \cdot \left( \alpha B + P \right) + \max \left(0, \frac{4}{5} \left( -\alpha (B+P) + P \right) \right) \] 這是兩段折線組成的函數,轉折點在 \(\alpha = \frac{P}{P + B}\)。 \[ \begin{align} \max_{\beta} \mathbb{E}(\text{Payoff}_B) &= \begin{cases} \frac{1}{5} \cdot \left( \alpha B + P \right) + \frac{4}{5} \left( -\alpha (B+P) + P \right), & \text{if } \alpha < \frac{P}{P + B} \\ \frac{1}{5} \cdot \left( \alpha B + P \right), & \text{if } \alpha \ge \frac{P}{P + B} \\ \end{cases} \\ &= \begin{cases} P - \alpha \frac{3B+4P}{5}, & \text{if } \alpha < \frac{P}{P + B} \\ \frac{1}{5} \cdot \left( \alpha B + P \right), & \text{if } \alpha \ge \frac{P}{P + B} \\ \end{cases} \\ \end{align} \]
這個公式的意思是,若 B 針對 A 的策略 \(\alpha\) 做出最佳回應 (也就是 \(\beta = \beta(\alpha)\) 會隨著 \(\alpha\) 而改變),將 B 的 Payoff 期望值看成是 \(\alpha\) 的函數。
這下輪到 A 選擇。 A 要選一個 \(\alpha\) 來最小化 B 的期望值。
可以看出,折線的前半段是遞減的,後半段是遞增的,所以最小值會出現在轉折點 \(\alpha = \frac{P}{P + B}\)。
而最小值為: \[ \min_{\alpha} \max_{\beta} \mathbb{E}(\text{Payoff}_B) = \frac{1}{5} \cdot \left( \frac{P}{P + B} B + P \right) \] 這是這個遊戲的 Value。對 B 而言是正的,代表 B 有利可圖。
A 的最佳進攻策略:
完全同樣的論述,可以解出 A 的最佳進攻策略。
來快速看一下,這時就用到 \(\eqref{eq:E_for_alpha}\),這是一個關於 \(\alpha\) 的線性函數。
如果 \(\beta\) 太小,A 就會選擇 \(\alpha = 1\) (Always Call);如果 \(\beta\) 太大,A 就會選擇 \(\alpha = 0\) (Always Fold)。 \[ \alpha = \alpha(\beta) = \begin{cases} 1, & \text{if } \beta < \frac{B}{4(P + B)} \\ 0, & \text{if } \beta > \frac{B}{4(P + B)} \\ \text{any value in } [0,1], & \text{if } \beta = \frac{B}{4(P + B)} \\ \end{cases} \] 代回去看看: \[ \min_{\alpha} \mathbb{E}(\text{Payoff}_B) = \frac{1}{5} P \left( 1 + 4\beta \right) + \min \left(0, \frac{B}{5} - \frac{4}{5} \beta (B + P) \right) \] 這也是兩段折線組成的函數,轉折點在 \(\beta = \frac{B}{4(P + B)}\)。 \[ \begin{align} \min_{\alpha} \mathbb{E}(\text{Payoff}_B) &= \begin{cases} \frac{1}{5} P \left( 1 + 4\beta \right), & \text{if } \beta < \frac{B}{4(P + B)} \\ \frac{1}{5} P \left( 1 + 4\beta \right) + \left( \frac{B}{5} - \frac{4}{5} \beta (B + P) \right), & \text{if } \beta \ge \frac{B}{4(P + B)} \\ \end{cases} \\ &= \begin{cases} \frac{1}{5} P \left( 1 + 4\beta \right), & \text{if } \beta < \frac{B}{4(P + B)} \\ \frac{1}{5} (P + B) - \frac{4P}{5} \beta, & \text{if } \beta \ge \frac{B}{4(P + B)} \\ \end{cases} \\ \end{align} \] 現在要找 \(\beta\) 來最大化這個函數。因為前半段是遞增的,後半段是遞減的,所以最大值會出現在轉折點 \(\beta = \frac{B}{4(P + B)}\)。 \[ \max_{\beta} \min_{\alpha} \mathbb{E}(\text{Payoff}_B) = \frac{1}{5} P \left( 1 + 4 \cdot \frac{B}{4(P + B)} \right) = \frac{1}{5} \cdot \left( \frac{P}{P + B} B + P \right) \] 這結果跟剛剛一樣,代表我們找到了納許均衡點。同時,我們也手動驗證了 Min-Max 定理在這個賽局中成立。
結論
由此得出,納許均衡點為: \[ \begin{align} \alpha^* &= \frac{P}{P + B} \\ \beta^* &= \frac{B}{4(P + B)} \\ \end{align} \]
這個結論可以細品一下: 如果 \(\alpha\) 固定選在 \(\alpha^*\) 上,B 怎麼選 \(\beta\) 都無所謂;如果 \(\beta\) 固定選在 \(\beta^*\) 上,A 怎麼選 \(\alpha\) 都無所謂。
但是若有一方偏離這個點,則另一方就可以透過極端策略來進行剝削。但同時也暴露出自己的弱點。
這個架構跟剪刀石頭布是幾乎一樣的。
速算法: 無異原理 (Indifference Principle)
費了很大一番功夫,我們終於確認納許均衡點。但每次都要列出落落長的全機率公式再微分實在太慢了。
我們剛才發現一個關鍵性質:「若 A 取 \(\alpha = \frac{P}{P + B}\) 時,則 B 對於 \(\beta\) 的選擇是無所謂的(期望值相同)。」
這其實就是微積分中「極值點斜率為零」的賽局版本。既然 B 在均衡點時,對於「詐唬」或「不詐唬」的期望值應該一樣(否則他就會全部倒向其中一邊),我們可以直接針對 B 的決策節點 (Decision Node) 列式。
怎麼心算 A 的最佳跟注率 (\(\alpha\))?
我們要讓 B 在「拿到爛牌」時,對於 Check 和 Bluff 感到無差別。 (注意:我們不需要考慮 B 拿到好牌的情況,因為那裡他一定會下注,沒有決策難題)。
- 若 B 選擇 Check (放棄): 他直接輸掉,收益為 \(0\)。
- 若 B 選擇 Bluff (下注 \(B\)):
- 有 \((1-\alpha)\) 的機率 A 蓋牌,B 贏得底池 \(P\)。
- 有 \(\alpha\) 的機率 A 跟注,B 被抓包,輸掉賭注 \(B\)。
令兩者期望值相等: \[0 = (1-\alpha) \cdot P + \alpha \cdot (-B)\]
一眼就能看出這就是著名的 Pot Odds 公式變體: \[\alpha \cdot B = (1-\alpha) \cdot P \implies \alpha = \frac{P}{P+B}\]
這告訴我們一個很反直覺的真理: A 的最佳防守頻率 (\(\alpha\)),完全取決於底池賠率,跟 B 到底有多少機率拿到同花毫無關係!
怎麼心算 B 的最佳詐唬率 (\(\beta\))?
我們要讓 A 在面對下注時,對於 Call (跟注) 和 Fold (蓋牌) 感到無差別。
若 A 選擇 Fold: 收益為 \(0\) (不賠不賺,底池送給 B)。
若 A 選擇 Call: 這時候 A 贏或輸,取決於 B 到底是真的有牌 (Value Bet) 還是偷雞 (Bluff)。
- A 贏 (B 詐唬): 贏得底池 \(P\) 加上 B 的下注 \(B\)。
- A 輸 (B 有同花): 輸掉跟注金額 \(B\)。
為了讓 A 無差別 (EV of Call = 0),A 贏的獲利期望值 必須等於 A 輸的風險期望值。
\[ \text{Prob(Bluff)} \times (P + B) = \text{Prob(Value)} \times B \]
移項整理一下,這就是著名的 賠率平衡公式 (bluff-to-value ratio):
\[ \frac{\text{Prob(Bluff)}}{\text{Prob(Value)}} = \frac{B}{P + B} \]
這告訴我們:B 的 詐唬頻率 對比 價值注頻率,必須剛好等於 A 的跟注賠率 (Pot Odds)。
現在把題目中的機率帶進去: * Prob(Value): B 拿到同花且下注。機率是 \(\frac{1}{5} \times 1\) (有牌必打)。 * Prob(Bluff): B 沒拿到同花且下注。機率是 \(\frac{4}{5} \times \beta\) (沒牌詐唬)。
代回公式: \[ \frac{\frac{4}{5}\beta}{\frac{1}{5}} = \frac{B}{P+B} \]
左邊消掉 5: \[ 4\beta = \frac{B}{P+B} \]
解得: \[ \beta = \frac{1}{4} \cdot \frac{B}{P+B} \]
這結果跟我們之前用微積分算出來的一模一樣!
[Optional] 註記:
這裡看上去好像真的只要解平衡點就好了,而且 A 的 抓詐唬頻率真的真 B 的反敗為勝機率毫無關係 (在公式上)。
但我們想像一種情況,假設 B 反敗為勝的機率變得超高 (比方說 4/5),而且池底相對小,比方說 \(P = 80\) 元,\(B = 80\) 元。那其實 A 的最佳跟注率並非 \(\alpha = \frac{80}{80+80} = 0.5\),而是 0 。這也很符合直覺,因為高機率會輸。這可以用上面代回去論證的方法看出來: 原本是 前半段函數斜率是負的,後半段是正的,但現在兩段都是正的,所以 A 的最佳策略是 \(\alpha = 0\)。
不過這種情況在實際的撲克中很少見,因為在這種設定下(只有B知道自己是否獲勝),反敗為勝的機率通常不會太高,也就是池底大部分的牌都可以讓 B 組出好牌。這違反了撲克的常識。