一天證明一個 Normal Distribution 的性質 Day8: C n 取 k
「從 52 張撲克牌中,隨機抽 7 張牌,有多少種不同的組合方式?」
「\(\displaystyle \binom{52}{7}\),嗯… 可能要按一下計算機?」
「不用,我們可以利用常態分佈的近似來心算看看!」
\[ \binom{52}{7} = \frac{52\times 51 \times 50 \times 49 \times 48 \times 47 \times 46}{7 \times 6 \times 5 \times 4 \times 3 \times 2 \times 1} \]
常態分佈近似?
我們要用機率的觀點,計算 \(\frac{1}{2^{52}}\binom{52}{7}\)。也就是擲 \(52\) 枚公正的硬幣,有多少機率會出現 \(7\) 個正面朝上?
- 平均值: \(Np = 52 \times \frac{1}{2} = 26\)
- 變異數: \(Np(1-p) = 52 \times \frac{1}{2} \times \frac{1}{2} = 13\)
- 標準差: \(\sqrt{Np(1-p)} = \sqrt{13} \approx 3.6\)
所以有正面朝上的個數分布大約就是: \(\mathcal{N}(26, 3.6^2)\)。
但因為常態分佈是描述連續的機率密度,而我們擲硬幣是離散的。
所以應該是要算:從 \(6.5\) 到 \(7.5\) 的區間下的常態分佈面積,但也可以用 \(x=7\) 那個點的機率密度來近似(想成用寬度為1的長方形近似)。
\[ \begin{aligned} f(z) &= \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(z-\mu)^2}{2\sigma^2}} = \frac{1}{\sqrt{2\pi\times 13}} e^{-\frac{(7-26)^2}{2 \times 13}} = \frac{1}{\sqrt{26\pi}} e^{-\frac{361}{26}} \\ &\approx \frac{1}{\sqrt{80}} \times e^{-14} \end{aligned} \] 記得還要乘上 \(2^{52}\) 才是組合數。
這邊需要一些常用的近似值:
- \(2^{10} \approx 10^3\)
- \(e^3 \approx 20\)
- \(e^7 \approx 1100\)
所以估計 \[ \binom{52}{7} \approx 2^{52} \times \frac{1}{\sqrt{80}} \times e^{-14} \approx \frac{4 \times 10^{15}}{9 \times 10^6 \times 1.1^2} \approx 4 \times 10^8 \]
實際上 \(\binom{52}{7} = 133784560\),我們的估計值大約是 \(3\) 倍左右! 意外地不準! 為什麼?
梯形近似
其實以心算來說已經夠了,如果再算更複雜還不如用電腦算。 但我們實在很想知道,這個不準的來源,是來自於哪裡?
- 常態分佈 \(\approx\) 二項分佈。
- 用長方形(寬度 1) 近似曲線底下的面積。
我們來算算看梯形面積會不會好一點? (P.S 這裡已經失去了速算的意義,單純研究誤差來源)
\[ \begin{aligned} \frac{f(6.5)+f(7.5)}{2} &= \frac{1}{2} \frac{1}{\sqrt{2\pi\times 13}} \left( e^{-\frac{(6.5-26)^2}{2 \times 13}} + e^{-\frac{(7.5-26)^2}{2 \times 13}} \right) \\ &\approx \frac{1}{2\times 9} \left( e^{-14.625} + e^{-13.1} \right) \\ &\approx \frac{1}{18} \left( \frac{1}{2.2 \times 10^6} + \frac{1}{5 \times 10^5} \right) \approx \frac{1}{18} \times \frac{1.22}{5 \times 10^5} \approx \frac{1}{7.4 \times 10^6} \end{aligned} \] 剛才是約 \(\frac{1}{9 \times 10^6}\),已經是高估三倍了,這次是 \(\frac{1}{7.4 \times 10^6}\),誤差又更大了!!
因為 convexity 的關係,在超過 \(\mu \pm \sigma\)後,常態分佈曲線已經是『下凸』 (Convex / Concave Up,像碗一樣向上彎),梯形面積反而比長方形面積誤差還更大,所以誤差更大了。當然可以用切線近似之類的,但本質上最大問題,在於常態分佈本身在離 \(\mu\) 很遠的地方,已經無法很好近似二項分佈了。
(P.S. 雖然說常態分佈的尾巴比二項分布還要厚,但是已經比其他真實世界的分佈還薄很多,例如股市漲跌幅、或是Student-t分布。)
大偏差理論 Large Deviation Theory
我們花了一番力氣證明,無論是用長方形還是梯形去近似常態分佈下的面積,都無法修復 3 倍以上的誤差。這意味著:問題不在於積分技巧,而在於模型本身。
這個現象在機率論裡有一個專門的學科在研究,叫做 大偏差理論 (Large Deviation Theory, LDT)。
我們擲 52 次硬幣,平均正面次數 \(\mu=26\)。但我們卻想計算 \(k=7\) 的機率。
\(k=7\) 是一個極端事件 (Extreme Event)。雖然常態分佈是根據中央極限定理(Central Limit Theorem, CLT)得出的,它保證了當 \(n\) 夠大時,中央區域的表現很像常態分佈。但是,CLT 並不保證尾部的行為。
LDT 研究的正是這些極端事件發生的機率是如何指數級地衰減。它告訴我們,當事件離平均值越遠,常態分佈的近似(它假設了 \(e^{-x^2}\) 的衰減)就會嚴重失真。對於 \(z \approx -5.3\) 這種極端偏差,我們必須使用更精確的工具。
根據 大偏差理論 (Large Deviation Theory) 中的 Cramér’s Theorem,對於樣本平均數 \(\bar{X}_n\) 偏離期望值 \(p\) 的機率,其衰減速度並不是常態分佈描述的 \(e^{-x^2}\),而是由 速率函數 (Rate Function) \(I(x)\) 決定的: \[ P(\bar{X}_n \approx x) \approx e^{-n I(x)} \] 對於伯努利分佈(投硬幣),這個速率函數 \(I(x)\) 其實就是 相對熵 (KL Divergence): \[ I(x) = x \ln \frac{x}{p} + (1-x) \ln \frac{1-x}{1-p} \] 在我們的例子中,\(n=52, p=0.5, x=7/52\)。如果我們計算 \(e^{-n I(x)}\),你會發現它剛好等於我們後面要用的那個「神奇修正項」: \[ e^{-52 \cdot I(7/52)} = \left(\frac{7/52}{1/2}\right)^{-7} \left(\frac{45/52}{1/2}\right)^{-45} \times (\text{常數}) \] 也就是說,LDT 準確預測了常態分佈在尾部會失效,並且告訴我們失效的幅度(修正項)剛好就是相對熵的指數!為了具體計算這個值,我們可以使用 LDT 常用的技巧:指數傾斜 (Exponential Tilting),也就是把機率測度變換到讓事件變成「中心」的地方!
既然在原本的機率分佈 (\(p=0.5\)) 下, \(k=7\) 是個看不清楚的邊緣地帶,那我們不如創造一個新的平行宇宙,在這個宇宙裡,\(k=7\) 才是最正常的事件。
我們可以定義一個新的二項分佈,讓它的參數變成 \(p'=\frac{7}{52}\),這樣我們就可以把 \(k=7\) 這個事件,轉換成在新分佈下的「平均事件」。
在新的分布下,
- 平均值 \(\mu' = Np = 52 \times \frac{7}{52} = 7\),
- 變異數 \(\sigma'^2 = Np(1-p) = 52 \times \frac{7}{52} \times \left(1 - \frac{7}{52}\right) = 7 \times \frac{45}{52} \approx 6.06\),
\[ P'(X=7) = \binom{52}{7} (p')^7 (1-p')^{45} \]
根據我們的常態分佈近似(因為現在 7 是平均值,也就是峰值,近似會非常準確): \[ P'(X=7) \approx \frac{1}{\sqrt{2\pi \sigma'^2}} \]
將兩式合併,我們就可以反推組合數 \(\binom{52}{7}\): \[ \begin{aligned} \binom{52}{7} &\approx \frac{1}{\left(\frac{7}{52}\right)^7 \left(\frac{45}{52}\right)^{45}} \times \frac{1}{\sqrt{2\pi \times 52 \frac{7}{52} \frac{45}{52} }} \\ &\approx \frac{1}{\sqrt{2\pi}} \frac{52^{52}}{7^7 \times 45^{45}} \times \frac{\sqrt{52}}{\sqrt{7\times 45}} \\ &= \frac{1}{\sqrt{2\pi}} \frac{\sqrt{52}}{\sqrt{7\times 45}} e^{52 H(\frac{7}{52})} \end{aligned} \]
這正是 Stirling Formula 的形式! 我們繞了一大圈,利用機率觀點的「換底操作」,重新發現了階乘近似公式。雖然這完全失去了心算的意義,但這揭示了常態分佈、大偏差理論與組合數學之間深刻的連結。
作為收尾,我們比較一下這跟剛才 \(p=1/2\) 時的近似值: \[ \begin{aligned} \binom{52}{7} &\approx 2^N \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(k-\frac{N}{2})^2}{2 \sigma^2}} \qquad\text{ , where } \sigma^2=\frac{N}{4} \\ &= \frac{1}{\sqrt{2\pi}} \frac{1}{\sqrt{\frac{N}{4}}} e^{N\ln(2) - \frac{(k-\frac{N}{2})^2}{\frac{N}{2}}} \\ &= \frac{1}{\sqrt{2\pi}} \frac{2}{\sqrt{N}} e^{N \left[ \ln(2) - 2\left(\frac{1}{2} - \frac{k}{N}\right)^2 \right] } \\ \end{aligned} \]
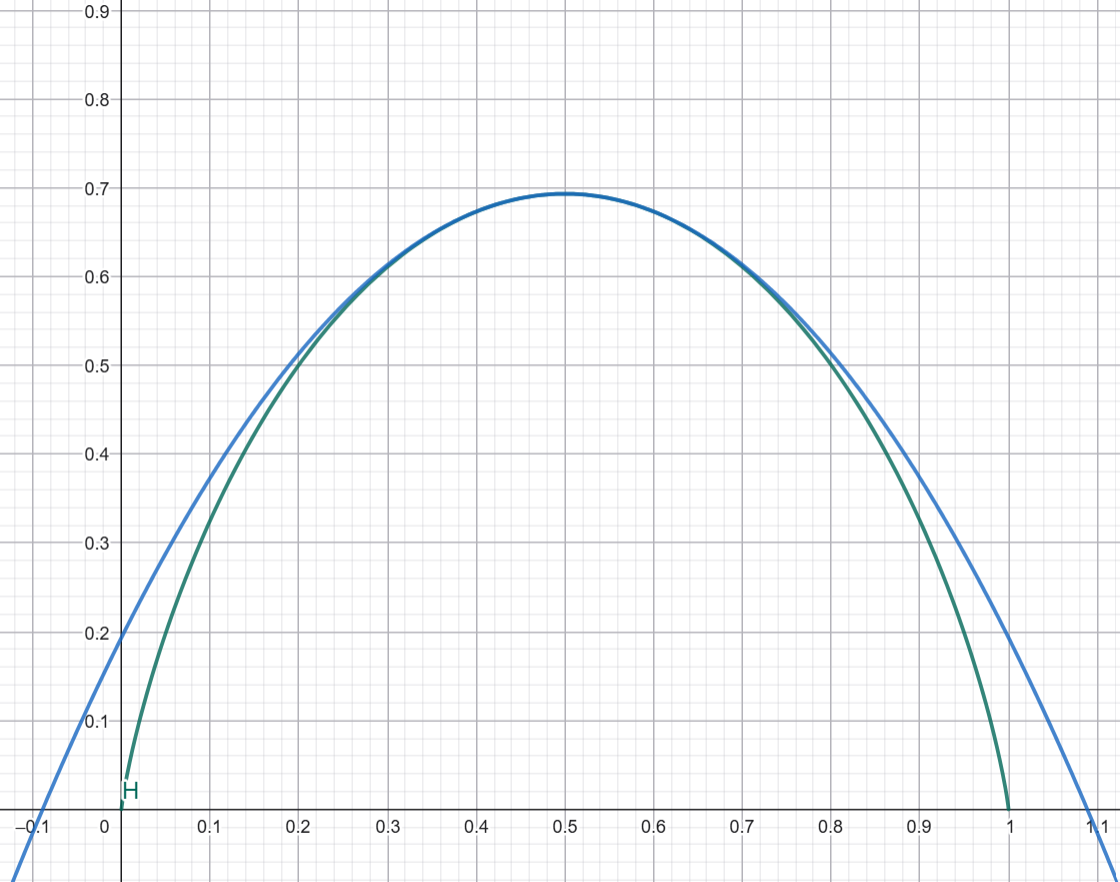
假設我們不看係數的誤差,令 \(x=\frac{k}{N}\),比較兩個指數部分的差異,正確的是用 \(H(x)\),而錯誤近似的是用 \(\ln(2) - 2\left(\frac{1}{2} - x\right)^2\),是一個二次函數的近似。
這樣就看得很清楚了,當 \(x=1/2\) 兩者相等,但當 \(x\) 遠離 \(1/2\) 時,二次函數的近似會越來越高估 \(H(x)\) 的值,導致組合數被高估。