Conjugate Prior
什麼是共軛分佈?從丟硬幣開始說起
在貝氏統計 (Bayesian statistics) 中,我們經常需要估計一個未知參數的機率分佈。
讓我們從一個最經典的問題開始:丟硬幣。
假設我們有一枚硬幣,它有 \(p\) 的機率正面朝上。我們不知道 \(p\) 究竟是多少(可能是一枚完美的硬幣,\(p=0.5\),也可能是一枚被動過手腳的硬幣)。
為了估計 \(p\),我們開始做實驗:連續丟這枚硬幣。 假設我們總共丟了 \(N\) 次,結果是 \(\alpha\) 次正面和 \(\beta\) 次反面(其中 \(\alpha + \beta = N\))。
現在,問題來了:我們對 \(p\) 的最佳估計是什麼?
什麼才算「最好」的估計?
要回答這個問題,我們必須先釐清「最好」是什麼意思。在統計學上,至少有兩種截然不同的思考流派。
觀點一:最大似然估計 (Maximum Likelihood Estimation, MLE)
這是「頻率學派」的觀點。他們會問:
哪一個 \(p\) 值,最有可能產生我們觀測到的實驗結果(\(\alpha\) 次正面,\(\beta\) 次反面)?
我們把觀測到的數據 (Data) 稱為 \(D\)。這個觀點的目標是找到一個 \(p\),來最大化「給定 \(p\) 之後,觀測到 \(D\)」的機率。這個機率在統計上稱為似然 (Likelihood)。
寫成數學式,我們要找的就是: \[ \text{arg}\max_{p} { \mathbb{P}(D \mid p) } \]
(在這個硬幣問題中,\(\mathbb{P}(D \mid p) = p^\alpha (1-p)^\beta\)。懂微積分的話,你會發現答案是 \(p = \frac{\alpha}{\alpha+\beta}\),這非常直觀。)
觀點二:貝氏推論 (Bayesian Inference)
這是「貝氏學派」的觀點。他們會說:
在我們開始丟硬幣之前,我們對 \(p\) 就已經有一些初步的信念(比如,它可能是一枚公平硬幣,所以 \(p\) 應該在 0.5 附近)。
然後,我們利用實驗數據 \(D\) 來更新這個信念。
在這個框架下,\(p\) 不再是一個固定的未知數,而是一個隨機變數,它自己也有一個機率分佈。
這裡有三個核心概念:
- 事前分佈 (Prior Distribution) \(\mathbb{P}(p)\): 在觀測到任何數據之前,我們對 \(p\) 的信念分佈。
- 似然 (Likelihood) \(\mathbb{P}(D \mid p)\): 同 MLE,代表「在某個 \(p\) 之下,觀測到數據 \(D\)」的機率。
- 事後分佈 (Posterior Distribution) \(\mathbb{P}(p \mid D)\): 在觀測到數據 \(D\) 之後,我們對 \(p\) 更新後的信念分佈。
貝氏定理:更新信念的關鍵
貝氏學派的精髓,就是透過「貝氏定理」來完成這個信念的更新:
\[ \mathbb{P}(p \mid D) = \frac{\mathbb{P}(D \mid p) \cdot \mathbb{P}(p)}{\mathbb{P}(D)} \]
這個公式可能看起來有點嚇人,但它的核心思想很簡單:
事後分佈 \(\propto\) 似然 \(\times\) 事前分佈 (Posterior \(\propto\) Likelihood \(\times\) Prior)
為什麼我們需要「共軛分佈」?
貝氏推論非常強大,但它有個很現實的數學問題:
要計算事後分佈 \(\mathbb{P}(p \mid D)\),我們需要計算分母 \(\mathbb{P}(D)\)。 \(\mathbb{P}(D) = \int \mathbb{P}(D \mid p) \mathbb{P}(p) \text{d}p\)。這個積分(或離散情況下的加總)常常非常複雜,甚至算不出來。
這就讓早期的統計學家很頭痛。直到他們發現了一個「捷徑」。
想像一下:
如果我們精心挑選一個「事前分佈」\(\mathbb{P}(p)\),使得它在乘上「似然函數」\(\mathbb{P}(D \mid p)\) 之後,得到的「事後分佈」\(\mathbb{P}(p \mid D)\) …
…竟然跟原來的「事前分佈」長得一模一樣(只是參數不同了)!
這就太神奇了!這代表:
- 計算超級簡單: 我們不需要去算那個可怕的積分,只需要套用簡單的「參數更新規則」就好。
- 迭代更新: 這次得到的「事後分佈」可以當作下一次實驗的「事前分佈」,形成一個不斷學習的循環。
這種「事前分佈」與「事後分佈」同屬於一個機率分佈家族的特性,就稱為共軛 (Conjugacy)。
我們稱:
這個「事前分佈」(Prior) 是該「似然函數」(Likelihood) 的「共軛事前分佈」(Conjugate Prior)。
回到我們最初的硬幣問題。
我們的「似然函數」\(\mathbb{P}(D \mid p)\) 是一個二項分佈 (Binomial Distribution) 的形式。
那麼,是否存在一個機率分佈,是二項分佈的「共軛事前分佈」呢?
答案是:有!
數學推導:為什麼 Beta 是二項分佈的共軛?
第 1 步:定義我們的「似然」 (Likelihood)
我們的實驗是丟硬幣,得到了 \(\alpha\) 次正面和 \(\beta\) 次反面。 給定一個特定的 \(p\)(正面機率),發生這件事的機率(即「似然」)是一個二項分佈 (Binomial Distribution):
\[ \mathbb{P}(D \mid p) = \binom{\alpha+\beta}{\alpha} p^\alpha (1-p)^\beta \]
在貝氏推導中,我們只關心這個公式「作為 \(p\) 的函數」長什麼樣子。那個 \(\binom{\alpha+\beta}{\alpha}\) 是一個常數(跟 \(p\) 無關),所以我們可以把它合併到 \(\propto\) (正比於) 符號中:
Likelihood: \(\mathbb{P}(D \mid p) \propto p^\alpha (1-p)^\beta\)
第 2 步:介紹主角「Beta 分佈」
現在,我們需要尋找一個「事前分佈」\(\mathbb{P}(p)\),它乘上 \(p^\alpha (1-p)^\beta\) 之後,長得會跟自己很像。
仔細看 \(p^\alpha (1-p)^\beta\) 這個形式… 如果我們的「事前分佈」也長成「\(p\) 的幾次方」乘上「\((1-p)\) 的幾次方」,那它們相乘時,不就可以很漂亮地合併指數嗎?
這正是 Beta 分佈登場的時刻!
Beta 分佈的機率密度函數 (PDF) 定義在 \(p \in [0, 1]\) 之間(這剛好就是機率 \(p\) 的合理範圍),它有兩個超參數 (hyperparameters),我們叫它們 \(a\) 和 \(b\):
Prior: \(\mathbb{P}(p) = \text{Beta}(p \mid a, b) = \frac{1}{B(a, b)} p^{a-1} (1-p)^{b-1}\)
- \(a\) 和 \(b\) 必須大於 0。
- \(B(a, b)\) 是一個常數(Beta 函數,\(\frac{\Gamma(a)\Gamma(b)}{\Gamma(a+b)}\)),用來確保整個分佈的總機率積分為 1。
- 直觀上,你可以把 \(a\) 想像成我們在實驗前「信念中」的正面次數, \(b\) 想像成「信念中」的反面次數。
和似然函數一樣,在 \(\propto\) 的世界裡,我們可以暫時忽略常數 \(B(a, b)\):
Prior: \(\mathbb{P}(p) \propto p^{a-1} (1-p)^{b-1}\)
第 3 步:施展貝氏魔法!(推導事後分佈)
我們把 Likelihood 和 Prior 相乘:
\[ \begin{aligned} \mathbb{P}(p \mid D) &\propto \mathbb{P}(D \mid p) \times \mathbb{P}(p) \\ &\propto [p^\alpha (1-p)^\beta] \times [p^{a-1} (1-p)^{b-1}] \\ &\propto p^{(\alpha + a) - 1} \times (1-p)^{(\beta + b) - 1} \end{aligned} \]
第 4 步:揭曉答案
請停下來,仔細看看我們得到的結果:
事後分佈: \(\mathbb{P}(p \mid D) \propto p^{(a + \alpha) - 1} \cdot (1-p)^{(b + \beta) - 1}\)
再回頭看看我們的事前分佈:
事前分佈: \(\mathbb{P}(p) \propto p^{a - 1} \cdot (1-p)^{b - 1}\)
它們的數學形式一模一樣!
這證明了事後分佈仍然是一個 Beta 分佈。只不過,它的參數從 \((a, b)\) 更新成了 \((a + \alpha, b + \beta)\)。
結論:
這個推導告訴我們一個美妙的更新規則:
如果你對 \(p\) 的「事前信念」是 \(\text{Beta}(a, b)\),
接著你觀測到了 \(\alpha\) 次正面和 \(\beta\) 次反面,
那麼你對 \(p\) 的「事後信念」就是 \(\text{Beta}(a + \alpha, b + \beta)\)。
這就是共軛的魔力!
- 無需計算複雜積分: 我們完全繞過了 \(\mathbb{P}(D) = \int \mathbb{P}(D \mid p) \mathbb{P}(p) \text{d}p\) 這個大魔王。
- 直觀的更新: 我們的信念更新規則變成了簡單的加法。
- 新的 “正面” 參數 = 舊的 “正面” 信念 + 觀測到的正面次數
- 新的 “反面” 參數 = 舊的 “反面” 信念 + 觀測到的反面次數
- 迭代學習: 這個新的 \(\text{Beta}(a+\alpha, b+\beta)\) 分佈可以立刻作為下一次實驗的「事前分佈」,讓我們不斷地、無縫地用新數據更新我們的信念。
這完美地展示了貝氏統計如何將「先驗知識」與「觀測數據」優雅地結合起來。
共軛分佈(二):估計事件的「發生率」— Gamma 與 Poisson 的共舞
如果我們要估計的不是一個 0 到 1 的機率,而是一個**「率」 (rate)** 呢?例如:
- 一個客服中心,平均每小時接到多少通電話?
- 一個路口,平均每 10 分鐘會經過多少輛車?
- 你的程式碼,平均每 1000 行有多少個 bug?
這些事件的共同點是,它們在一個連續區間(時間、空間)內發生,我們可以去「計數」(count),理論上發生的次數可以 是 0, 1, 2, … 一直到無限大。
這類「計數」問題,正是 Poisson 分佈的主場。而當我們想對 Poisson 分佈的「率」(\(\lambda\)) 進行貝氏推論時,就輪到它的共軛夥伴——Gamma 分佈——登場了。
第一步:我們的「似然」— Poisson 分佈
和之前一樣,貝氏推論的第一步是建立我們的似然 (Likelihood)。
我們要估計的核心參數是 \(\lambda\) (lambda),代表「單位時間(或單位空間)內的平均事件發生率」。
Poisson 分佈告訴我們,如果平均率是 \(\lambda\),那麼在一個單位時間內,實際觀測到 \(k\) 次事件的機率為:
\[ \mathbb{P}(k \mid \lambda) = \frac{\lambda^k e^{-\lambda}}{k!} \] 假設我們進行了 \(n\) 次觀測(例如,我們觀察了 \(n\) 個小時),得到的數據是 \(D = \{x_1, x_2, \dots, x_n\}\),其中 \(x_i\) 是第 \(i\) 個小時觀測到的事件次數。
「給定 \(\lambda\)」,觀測到這整組數據 \(D\) 的聯合機率(似然)就是把所有機率乘起來: \[ \mathbb{P}(D \mid \lambda) = \prod_{i=1}^n \frac{\lambda^{x_i} e^{-\lambda}}{x_i!} \]
在貝氏推論中,我們只關心和 \(\lambda\) 相關的項。把上式重新整理:
\[ \begin{aligned} \mathbb{P}(D \mid \lambda) &\propto \left( \prod_{i=1}^n \lambda^{x_i} \right) \left( \prod_{i=1}^n e^{-\lambda} \right) \\ &\propto \lambda^{\sum x_i} \cdot e^{-n\lambda} \end{aligned} \]
令 \(S = \sum x_i\)(我們觀測到的總事件數),我們的似然函數可以簡潔地表示為:
Likelihood: \(\mathbb{P}(D \mid \lambda) \propto \lambda^S e^{-n\lambda}\)
第二步:我們的「事前」— Gamma 分佈
現在,我們需要為 \(\lambda\) 選擇一個事前分佈 (Prior)。 \(\lambda\) 作為一個「率」,它必須大於 0。我們需要一個定義在 \((0, \infty)\) 上的機率分佈。
更重要的是,我們希望這個事前分佈 \(\mathbb{P}(\lambda)\) 乘上似然 \(\lambda^S e^{-n\lambda}\) 之後,能得到一個形式相同的分佈。
看看似然的形式:\(\lambda\) 的某次方,再乘以 \(e\) 的 \(\lambda\) 負次方。 什麼分佈長這樣呢? 答案就是 Gamma 分佈!
Gamma 分佈由兩個超參數 \(\alpha\) (shape, 形狀) 和 \(\beta\) (rate, 率) 定義:
Prior: \(\mathbb{P}(\lambda) = \text{Gamma}(\lambda \mid \alpha, \beta) \propto \lambda^{\alpha-1} e^{-\beta\lambda}\)
直觀解釋 \(\alpha\) 和 \(\beta\): 你可以把 \(\alpha\) 想像成你的「事前信念中的總事件數」,而 \(\beta\) 是「事前信念中的總觀測單位數」。 例如,如果你「猜」這個率 \(\lambda\) 大約是 5(例如 5 通電話 / 1 小時),你可以設 \(\alpha=5, \beta=1\)。
第三步:貝氏魔法!推導「事後分佈」
我們再次使出貝氏定理的武器:
事後分佈 (Posterior) \(\propto\) 似然 (Likelihood) \(\times\) 事前分佈 (Prior)
\[ \begin{aligned} \mathbb{P}(\lambda \mid D) &\propto \mathbb{P}(D \mid \lambda) \times \mathbb{P}(\lambda) \\ &\propto [\lambda^S e^{-n\lambda}] \times [\lambda^{\alpha-1} e^{-\beta\lambda}] \\ &\propto \lambda^{(S + \alpha) - 1} \cdot e^{-(n + \beta)\lambda} \end{aligned} \]
它是不是 \(\lambda\) 的 (某數 - 1) 次方,再乘以 \(e\) 的 (負某數) \(\lambda\) 次方? 這正是一個新的 Gamma 分佈!
結論:優雅的更新規則
我們證明了:
如果你的事前信念是 \(\text{Gamma}(\alpha, \beta)\),
接著你觀測了 \(n\) 個單位,總共發生了 \(S = \sum x_i\) 次事件,
你的事後信念就會更新為 \(\text{Gamma}(\alpha_{\text{new}}, \beta_{\text{new}})\)。
更新規則超級簡單,只是加法:
- \(\alpha_{\text{new}} = \alpha + S\) (舊的事件數 + 新觀測到的事件數)
- \(\beta_{\text{new}} = \beta + n\) (舊的觀測單位 + 新觀測的單位數)
舉個例子:
- 事前 (Prior): 你是新來的客服經理,你猜測客服中心平均每小時接 10 通電話。你對這個猜測不太確定,所以你設定了 \(\text{Gamma}(\alpha=10, \beta=1)\) 當作你的事前信念。(信念強度 = 1 小時的觀測)
- 數據 (Data): 你實際去觀測了 5 個小時(\(n=5\)),接到的電話數分別是 \(\{12, 8, 11, 10, 9\}\)。
- 似然 (Likelihood): 觀測單位 \(n=5\)。觀測總數 \(S = 12+8+11+10+9 = 50\)。
- 事後 (Posterior):
- \(\alpha_{\text{new}} = \alpha + S = 10 + 50 = 60\)
- \(\beta_{\text{new}} = \beta + n = 1 + 5 = 6\)
- 你更新後的信念是 \(\text{Gamma}(60, 6)\)。
Gamma 分佈的期望值是 \(\alpha / \beta\)。
- 你原先的期望值是 \(\alpha/\beta = 10 / 1 = 10\) 通/小時。
- 你更新後的期望值是 \(\alpha_{\text{new}} / \beta_{\text{new}} = 60 / 6 = 10\) 通/小時。
在這個例子中,你的平均估計沒有變,因為你的觀測數據 (50/5 = 10) 剛好符合你的猜測!但是,你的信心大大增加了(Gamma(60, 6) 是一個比 Gamma(10, 1) 更尖、更窄的分佈),因為你的信念現在是基於 6 個小時的數據,而不僅僅是 1 個小時的猜測。
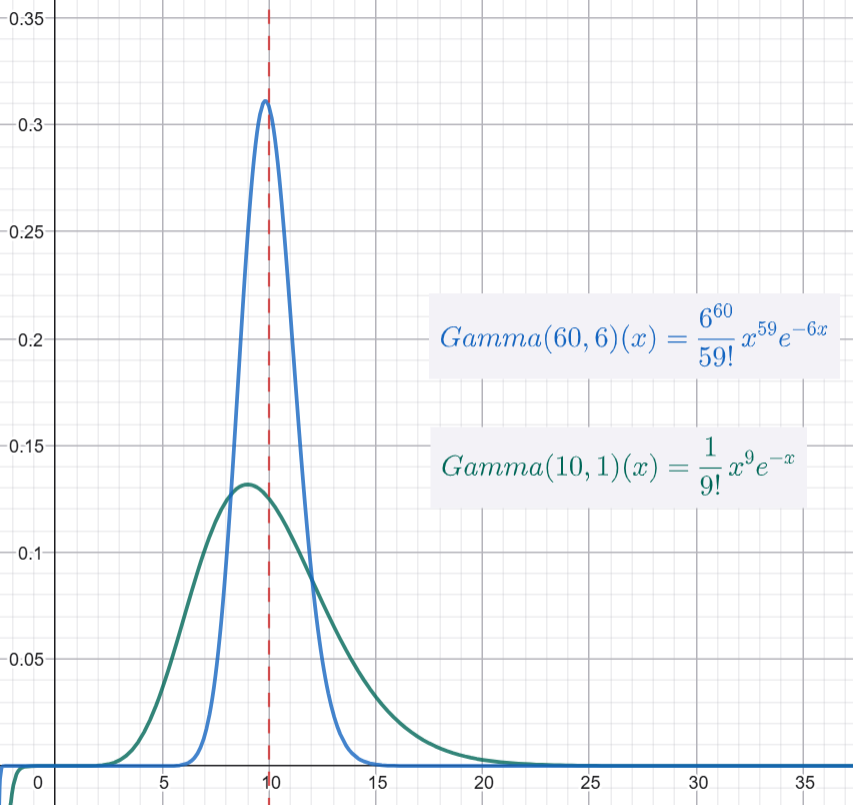
這就是 Gamma-Poisson 共軛家族的美妙之處:它提供了一個直觀且計算簡單的方法,讓我們不斷用新的「計數數據」來更新我們對「事件發生率」的信念。
共軛分佈(三):估計常態分佈的平均值與變異數 (Normal-Inverse-Gamma)
在前面的文章中,我們學會了如何:
- 用 Beta-Binomial 估計機率 (0 到 1 之間)。
- 用 Gamma-Poisson 估計頻率 (大於 0 的計數)。
現在,我們要來處理統計學中最常見的問題:估計一個平均值 (mean)。
- 一群學生的平均身高是多少?
- 一批產品的平均壽命是多久?
- 某支股票的平均日報酬率是多少?
這些測量值——身高、時間、報酬率——都是連續變數。而說到連續變數,統計學的王者,常態分佈 (Normal Distribution) \(\mathcal{N}(\mu, \sigma^2)\),就該登場了。
挑戰:兩個未知數
。但這裡有一個挑戰。不像 Binomial (只有 \(p\)) 或 Poisson (只有 \(\lambda\)) 只有一個參數,常態分佈 \(\mathcal{N}(\mu, \sigma^2)\) 描述了兩個我們都不知道的參數:
- 平均值 \(\mu\):我們主要想估計的目標。
- 變異數 \(\sigma^2\):數據的波動程度,我們通常也不知道。
我們希望能建立一個貝氏模型,讓我們對 \(\mu\) 和 \(\sigma^2\) 的「信念」在看到新數據 \(D = \{x_1, ..., x_n\}\) 後,能自動更新。
暖身: 從最大概似估計 (MLE) 看起
在進入貝氏模型之前,讓我們先用傳統的「最大概似估計 (Maximum Likelihood Estimation, MLE)」來暖身。這能幫助我們理解 Likelihood Function 的長相。
假設 \(D = \{x_1, ..., x_n\}\) 來自 \(\mathcal{N}(\mu, \sigma^2)\),Likelihood Function 為: \[ \begin{align} \mathbb{P}(D \mid \mu, \sigma^2) &= \prod_{i=1}^n \left( \frac{1}{\sigma\sqrt{2\pi}}e^{-\frac{(x_i-\mu)^2}{2\sigma^2}} \right) \\ &\propto \frac{1}{\sigma^n} e^{-\frac{\sum_{i=1}^n (x_i-\mu)^2}{2\sigma^2}} \end{align} \] 為了方便計算,我們取其負對數 (Negative Log-Likelihood): \[ \begin{align} - \ln(\mathbb{P}(D \mid \mu, \sigma^2)) &= \frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\mu)^2 + n \ln(\sigma) + \text{constant} \end{align} \] 這邊constant的意思是跟 \(\mu, \sigma\) 無關。
用 maximal likelihood 的觀點,這個 \(\mu, \sigma\) 的極值發生在哪裡? 我們記等式左邊這個 log-likelihood 為 \(f = - \ln(\mathbb{P}(D \mid \mu, \sigma^2))\)。令其偏微分各自為0。 \[ \begin{align} \frac{\partial f}{\partial \mu} &= \frac{1}{\sigma^2}\sum_{i=1}^n (\mu - x_i) = 0 \\ \frac{\partial f}{\partial \sigma} &= -\frac{1}{\sigma^3}\sum_{i=1}^n (x_i-\mu)^2 + \frac{n}{\sigma} = 0 \end{align} \] 解出來為 \[ \begin{align} \hat{\mu} &= \frac{1}{n}\sum_{i=1}^n x_i = \overline{x} \\ \hat{\sigma}^2 &= \frac{1}{n}\sum_{i=1}^n (x_i-\overline{x})^2 \end{align} \] (可以驗證一下,二階導數矩陣正定,所以 \(f\) 是取到最小值)
題外話:為什麼是除以 \(n\) 而不是 \(n-1\)? 一般說的樣本標準差是「除以 \(n-1\)」這裡推導出來怎麼是除以 \(n\)? 難道推導錯誤了嗎? 沒有,若要最大化似然,確實應該要除以 \(n\),而一般常用的除以 \(n-1\),那是我們希望這個 \(\sigma^2\) 是個無偏估計 (unbiased-estimation)。也就是說我們希望 \[ \mathbb{E}[\tilde{\sigma}^2] = \sigma^2 \] 把期望值的定義寫出來,也就是 \[ \int \tilde{\sigma}^2 \mathbb{P}(D \mid \mu, \sigma^2) dx_1...dx_n = \sigma^2 \] 也就是一般的樣本標準差 \(\tilde{\sigma}^2 = \frac{1}{n-1} \sum_{i=1}^n (x_i-\overline{x})^2\),是在所有無偏估計中,擁有最小variance的 (Why?)
貝式解法: Normal-Inverse-Gamma (NIG) 模型
好了,拉回我們的正題:貝氏更新。我們要找一個共軛事前分佈 \(\mathbb{P}(\mu, \sigma^2)\),使得它乘上 Likelihood \(\mathbb{P}(D \mid \mu, \sigma^2)\) 之後,得到的 Posterior \(\mathbb{P}(\mu, \sigma^2 \mid D)\) 仍然和 Prior 具有相同的形式。這個神奇的 Prior 就是 Normal-Inverse-Gamma (NIG) 分佈。它由四個超參數 \((\mu_0, \kappa_0, \alpha_0, \beta_0)\) 定義,其結構如下:
- 對 \(\sigma^2\) 的信念:我們假設 \(\sigma^2\) 服從一個 Inverse-Gamma 分佈: \[ \mathbb{P}(\sigma^2) \propto (\sigma^2)^{-\alpha_0-1}e^{-\frac{\beta_0}{\sigma^2}} \]
- 對 \(\mu\) 的信念 (給定 \(\sigma^2\)):我們假設 \(\mu\) 服從一個常態分佈,但這個常態分佈的變異數取決於 \(\sigma^2\): \[ \mathbb{P}(\mu \mid \sigma^2) \sim \mathcal{N}(\mu_0, \sigma^2/\kappa_0) \propto \frac{1}{\sigma /\sqrt{\kappa_0} } e^{-\frac{(\mu-\mu_0)^2}{2\sigma^2 / \kappa_0}} \]
這樣就描述了我們對 \(\mathbb{P}(\mu, \sigma^2)\) 的 joint distribution, \[ \begin{align} \mathbb{P}(\mu, \sigma^2) &= \mathbb{P}(\sigma^2) \cdot \mathbb{P}(\mu \mid \sigma^2) \\ &\propto (\sigma^2)^{-\alpha_0-1}e^{-\frac{\beta_0}{\sigma^2}} \frac{1}{\sigma /\sqrt{\kappa_0} } e^{-\frac{(\mu-\mu_0)^2}{2\sigma^2 / \kappa_0}} \end{align} \] 一樣是取negative log-likelihood看比較清楚: \[ \begin{align} -\ln(\mathbb{P}(\mu, \sigma^2)) &= \frac{\kappa_0(\mu-\mu_0)^2}{2\sigma^2} + \frac{\beta_0}{\sigma^2} + (2\alpha_0 + 3) \ln(\sigma) + \text{constant} \end{align} \]
精彩的來了,我們要算經過一筆資料 \(D\) 更新後的事後分布是否也是一樣的形式呢? 而四個超參數 \((\alpha_0, \beta_0, \mu_0, \kappa_0)\) 會如何變動呢?
\[ \begin{align} -\ln(\mathbb{P}(\mu, \sigma^2 \mid D)) &= -\ln(\mathbb{P}(D \mid \mu, \sigma^2)) -\ln(\mathbb{P}(\mu, \sigma^2)) + \text{constant} \\ &= \frac{1}{2\sigma^2}\sum_{i=1}^n (x_i-\mu)^2 + n \ln(\sigma) \\ &\qquad + \frac{\kappa_0(\mu-\mu_0)^2}{2\sigma^2} + \frac{\beta_0}{\sigma^2} + (2\alpha_0 + 3) \ln(\sigma) + \text{constant} \\ &= \left( \frac{n+\kappa_0}{2\sigma^2} \right)\mu^2 + \left( -\frac{(\sum_{i=1}^n x_i) + \kappa_0 \mu_0}{\sigma^2} \right)\mu \\ &\qquad + \frac{(\sum_{i=1}^n x_i^2) + \kappa_0 \mu_0^2 + 2\beta_0}{2\sigma^2} + (n+2\alpha_0+3)\ln(\sigma) + \text{constant} \end{align} \] 比較一下係數,可以依序解出 \[ \begin{align} \kappa_n &= n + \kappa_0 \\ \mu_n &= \frac{(\sum_{i=1}^n x_i) + \kappa_0 \mu_0}{n+\kappa_0} \\ \alpha_n &= \alpha_0 + \frac{n}{2} \\ \beta_n &= -\left( \frac{n+\kappa_0}{2} \right)\mu_n^2 + \frac{(\sum_{i=1}^n x_i^2) + \kappa_0 \mu_0^2 + 2\beta_0}{2} \quad\text{(by completing the square)} \\ &= - \frac{(\sum_{i=1}^n x_i + \kappa_0 \mu_0)^2}{2(n+\kappa_0)} + \frac{(\sum_{i=1}^n x_i^2) + \kappa_0 \mu_0^2 + 2\beta_0}{2} \end{align} \]
總結:更新規則與直觀解釋
我們成功了!Posterior \(\mathbb{P}(\mu, \sigma^2 \mid D)\) 確實保持了 Normal-Inverse-Gamma (NIG) 的形式,其超參數 \((\mu_n, \kappa_n, \alpha_n, \beta_n)\) 透過以下規則更新:
| 超參數 | 事前 (Prior) | 事後 (Posterior) 更新規則 |
|---|---|---|
| \(\kappa_n\) | \(\kappa_0\) | \(\kappa_n = \kappa_0 + n\) |
| \(\mu_n\) | \(\mu_0\) | \(\mu_n = \frac{\kappa_0 \mu_0 + n\overline{x}}{\kappa_0 + n}\) (其中 \(\overline{x} = \frac{1}{n}\sum x_i\)) |
| \(\alpha_n\) | \(\alpha_0\) | \(\alpha_n = \alpha_0 + \frac{n}{2}\) |
| \(\beta_n\) | \(\beta_0\) | \(\beta_n = \beta_0 + \frac{1}{2} \sum_{i=1}^n (x_i - \overline{x})^2 + \frac{n\kappa_0}{2(n+\kappa_0)}(\overline{x} - \mu_0)^2\) |
這代表什麼?,讓我們來直觀地解讀這些更新規則:
\(\kappa_n = \kappa_0 + n\): 我們對 \(\mu\) 的信心(\(\kappa\))等於「先前的信心」加上「新數據的點數」。這非常合理。
\(\mu_n = \frac{\kappa_0 \mu_0 + n\overline{x}}{\kappa_0 + n}\): 這是最漂亮的一條規則! 我們更新後的平均值 \(\mu_n\),是「先前平均值 \(\mu_0\)」和「數據平均值 \(\overline{x}\)」的加權平均。 權重分別是 \(\kappa_0\)(先前的信心)和 \(n\)(數據的數量)。如果 \(\kappa_0\) 很小(不確定的 prior),\(\mu_n\) 就會很接近 \(\overline{x}\)。如果 \(\kappa_0\) 很大(強烈的 prior),\(\mu_n\) 就會很接近 \(\mu_0\)。
\(\alpha_n = \alpha_0 + \frac{n}{2}\): 我們對 \(\sigma^2\) 的信念(\(\alpha\))也隨著數據點 \(n\) 而增加。
\(\beta_n = \beta_0 + \dots\): 我們對 \(\sigma^2\) 的信念(\(\beta\))更新,等於「先前的 \(\beta_0\)」加上「數據內部的變異 \(\sum (x_i - \overline{x})^2\)」再加上「數據平均值與先前平均值之間的差異 \((\overline{x} - \mu_0)^2\)」。這也完全符合直覺。
至此,我們完成推導了常態分佈的共軛模型!它讓我們能夠在 \(\mu\) 和 \(\sigma^2\) 都未知的情況下,優雅地更新我們的信念。